
In Part I of this series, we went through a brief history of OpenAI’s Generative Pre-trained Transformer large language model, and the case for open-source language models. Now that the ground has been set, we can jump in and discuss some of the openly available language models anyone can use to benefit from the recent improvements in NLP technology.
To evaluate the models, we will look at a few characteristics:
These models were created by volunteer researchers in response to the high cost and limited access to GPT-3’s large-scale language models (a cost that since then has decreased, worth noting). EleutherAI sought to create an open-source, community-driven alternative to GPT-3 that would be accessible to all researchers and developers. The models were trained on the Pile, EleutherAI’s open 800GB dataset EleutherAI. To create the dataset, EleutherAI gathered data from various open sources, such as Common Crawl, Wikipedia, and Project Gutenberg, as well as scraped data from a range of web domains and APIs.
We will discuss two models in particular: gpt-j-6b & gpt-neox-20b.
GPT-J-6B was released in June of 2021, with 6B parameters it is one of the first large-scale models out there. When deployed in its half-precision (16-bit floating point) mode, the model has an in-memory footprint of ~12GB, making it more affordable to run than most other models in this list. Despite its seemingly small size and old release date, GPT-J-6B holds up very well to this day and is a good starting point for those looking to get into the open-source GPT space.
GPT-NeoX-20B was released in February 2022. Having 20B parameters it was the largest open-source language model at the time. The larger model also has a larger memory footprint of ~40GB (for the half-precision mode).
For both models, it should be noted that they are not tuned to follow instructions (recall InstructGPT being a major milestone) and also comes with a disclaimer from the developers that the models are intended for research, and not from deployment without fine-tuning and supervision, and in particular that they may generate offensive text. You can play with the models here.
Google first introduced its Text-To-Text Transfer Transformer (T5) model architecture in 2020. At its time of release, the model was set to rival GPT 2 and has reportedly achieved better performance. The original T5 model was trained with a novel text-to-text approach, instead of training on a next-word completion task like GPT, it was trained using construction inputs and outputs to a unified text-to-text format, in a way that the model can better learn to perform more downstream tasks like translation and summarization.
In October 2021, Google introduced FLAN, a model fine-tuned for instructions. Google released FLAN seeking to improve zero-shot learning in LLM & reducing the overhead of what is now known as prompt engineering. The resulting model reportedly performed better than GPT3 on 21 tasks zero-shot learning tasks.
Flan UL2 is Google’s latest and greatest (to date) language model, released in March 2023. It is a 20B parameter model based on Google’s Unified Language Learner (UL2) pre-training process. According to Google, UL2 frames different objective functions for training language models as denoting tasks, which results in a unified framework that produces pre-trained models that are effective across differing datasets and setups. Coupling the Flan with UL2, and running on the T5 architecture, Flan UL2 is one of the most open-versatile language models out and has a memory footprint of ~40GB.
LLaMA is Meta’s LLM that was released in February 2023, under 4 versions differing by parameter count: 7B, 13B, 35B, and 65B, trained on ~1 trillion tokens. As of writing this, LLaMA is not yet officially released for the public, but rather available primarily for academia for research purposes (we didn’t try it ourselves).
Following its release, LLaMA was leaked to the public and has been made available on Hugging Face.
Intending to replicate InstructGPT’s success, following the release of LLaMA, researchers from the Department of Computer Science at Stanford University have released Alpaca, a 7B LLaMA fine-tuned on a dataset using GPT 3.5 itself. To create the dataset, the researchers generated 52k input questions that serve as examples of instruction-following prompts and then fed these inputs to GPT 3.5 via OpenAI’s API. This resulted in a model that “answers as ChatGPT would'' and displays impressive instruction-following performance on the surface. However, it was taken down by its team promptly to its release due to concerns about artificial hallucinations. Also, it couldn’t be used commercially as the method used to create the dataset violates the terms of use of OpenAI (as such, we didn’t try it ourselves either).
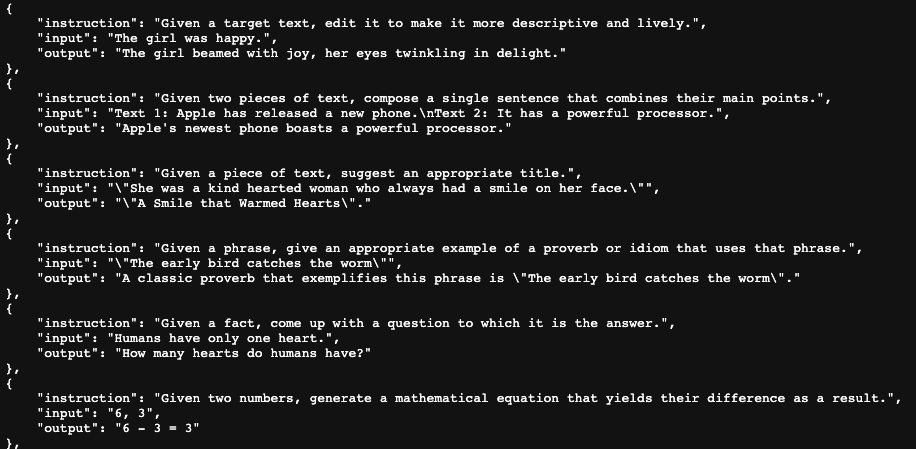
Some example data from the Alpaca dataset, has been made publicly available by the creators.
Following the buzz surrounding Alpaca, Databricks has released Dolly v2, a model based on another one of EleutherAI’s models, Pythia-12B, and fine-tuned on a ~15k instruction dataset crowdsourced by Databricks employees. According to Databricks, while the Dolly v2 dataset is smaller than the Alpaca dataset, it is of higher quality as it was curated by experts (rather than generated by GPT). The model comes in sizes of 3B, 7B, and 12B parameters, with the largest one having a memory footprint of 24GB.
We have wanted to refrain from describing in-depth any model we didn’t try ourselves, so with the exception of LLaMA and Alpaca, this list packs only some of the modern open-source language models. Some honorable mentions include the GLM models, a bilingual (Chinese & English) family of models from Tsinghua University, and Vicuna, a joint effort among researchers trained similarly to Alpaca.
The models mentioned in this article help us make the DoControl SaaS Security Platform smarter (as described in Part I of this blog series) while keeping our client’s sensitive data safe (within the boundaries of our own network). We hope this piece served as a good introduction for others to get started on a similar path (just don’t build Skynet, please)!
.webp)
Research-based benchmarks to assess risk across critical threat model

Discover why sensitive data discovery tools often trigger false alarms, causing frustration for InfoSec teams. Learn why this happens and how to find tools for accurate detections.

Learn about the three primary types of Zoom vulnerabilities: in-meeting, data storage, and system access risks. Safeguard your organization effectively against these threats.

SaaS solutions are integral for workflows, granting anytime access to critical data. Yet, without robust SaaS Access Control Management, businesses face significant security risks.